
本記事では、Dugan Automixerによる自動ミキシングを実装してみました。Dugan Automixer はいくつかの音響機器やソフトウェアに導入されている自動ミキシングのアルゴリズムです。
かなり昔に提案された方法ですが、現在の機器にも備わっているので、試しに実装しました。
Dugan Automixerとは
Dugan Automixer は複数のマイクが同時に使用される環境(会議など)において、リアルタイムで各マイクのゲイン(音量)を自動調整し、ハウリングや背景ノイズを抑えながらクリアな音声を維持する技術です。
1974年に Dan Dugan によって発明され、1976年に米国特許が成立しています(Gemini情報)。特許は1990年代に期限が切れたため、今ではパブリックドメインの技術となっています。
現在でもDugan Automixerは多くの音響機器に組み込まれています。具体例を出すとYAMAHA DM7シリーズ(2023)のデジタルミキサーやSound Devices の 最上位フィールドレコーダーである Scorpio(2019) などがあります。
様々なシーンに対応できる高い拡張性と柔軟性を備えた革新的なデジタルミキシングコンソール。…

オーバービュー 16個の超低ノイズ8シリーズマイクプリアンプ 32チャンネル、12バス、36トラック Dante I /…

アルゴリズム
Dugan Automixerのブロック図は下図のようになります。
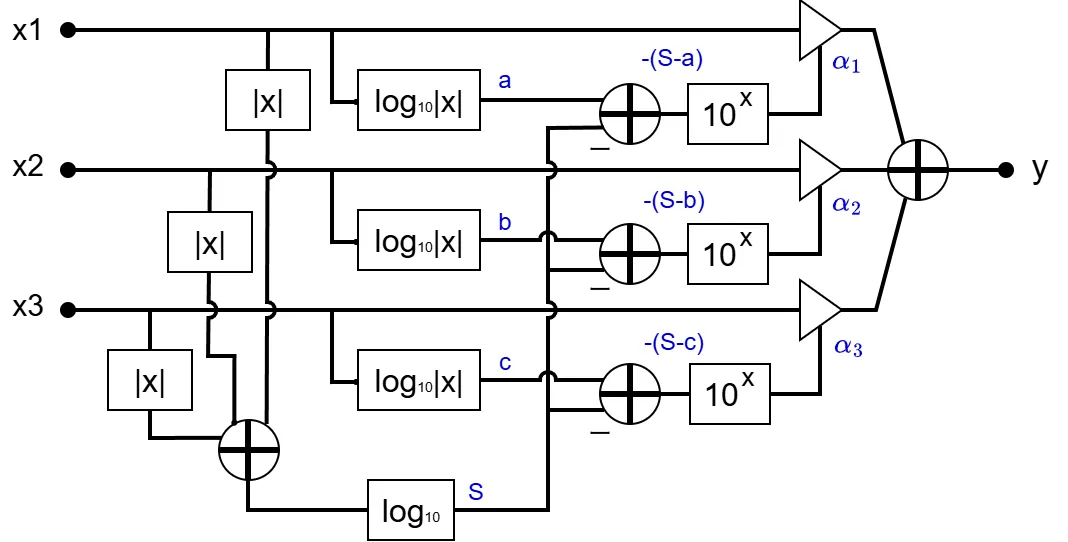
やっていることは単純で、各入力に対する減衰量 \(\ \alpha_i\ \)を以下の手順で決めています。
- 各入力の絶対値の log を計算(a,b,cを求める)
- 各入力の絶対値の合計を求めて、log を計算(Sを求める)
- 各入力の減衰量を -(S-x) (x=a,b,c) で計算
- 対数で表された減衰量をリニアに変換(\(10^{x}\)で変換)
特許はアナログ信号処理を使用しているため、割り算が難しくて対数を使っていますが、つまりは各入力\(\ x_{i}\ (i=1,\cdots,J)\ \)に対する減衰量 \(\alpha_{i}\ \)を以下の計算で求めています。
$$
\begin{equation}
\alpha_{i} = \frac{|x_{i}|}{\sum_{j=1}^{J} |x_{j}|}
\end{equation}
$$
このため、Dugan Automixerは入力信号の割合が大きいチャンネルほど減衰量が小さくなるようになっています。
注意:1サンプルごとに上記の減衰量を計算すると変動が激しくなるので、減衰量を平滑化する必要があります。
動作例
アルゴリズムだけだと、Dugan Automixerの動作をイメージしにくいと思うので、具体例を使って動作を説明します。
まず、3つのマイクで1人が話すとき(x1:-20dBFS, x2:-40dBFS, x3:-40dBFS)の減衰量は下図になります。
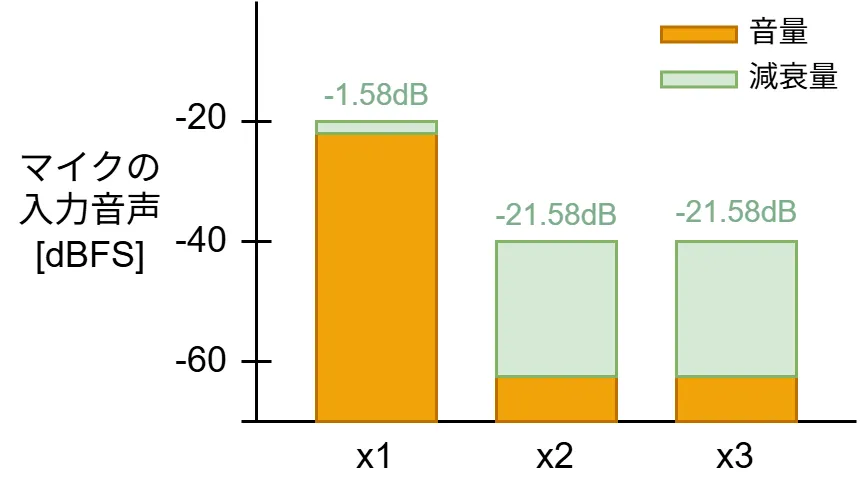
直接音が入力されるマイクでは減衰量はほとんどなく、回り込み(かぶり)の音を拾っている他のマイクでは-21dBほど大きく減衰します。
次に、3つのマイクで2人が話すとき(x1:-20dBFS, x2:-20dBFS, x3:-40dBFS)の減衰量は下図になります。
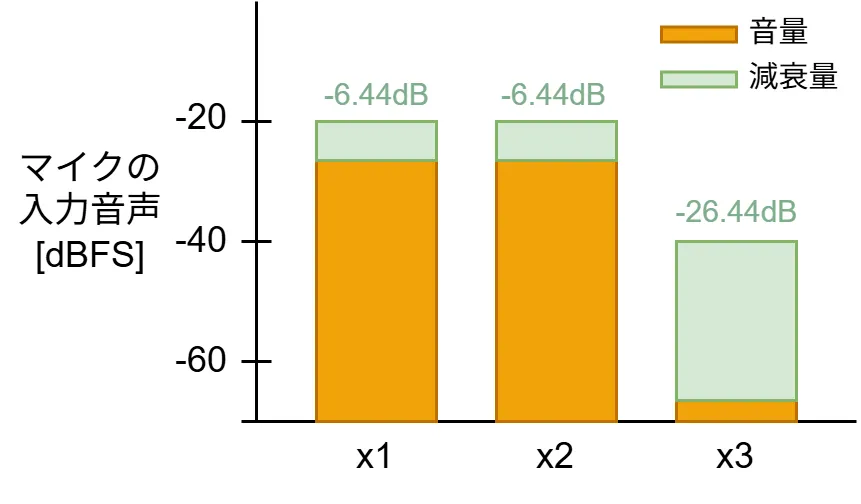
2人が話すときは、2つのマイクの入力音が少し減衰しつつ、他のマイクでは1人のときよりも大きく減衰します(-26dB減衰)。
3つのマイクで全員が話すとき(x1:-20dBFS, x2:-20dBFS, x3:-20dBFS)の減衰量は下図になります。
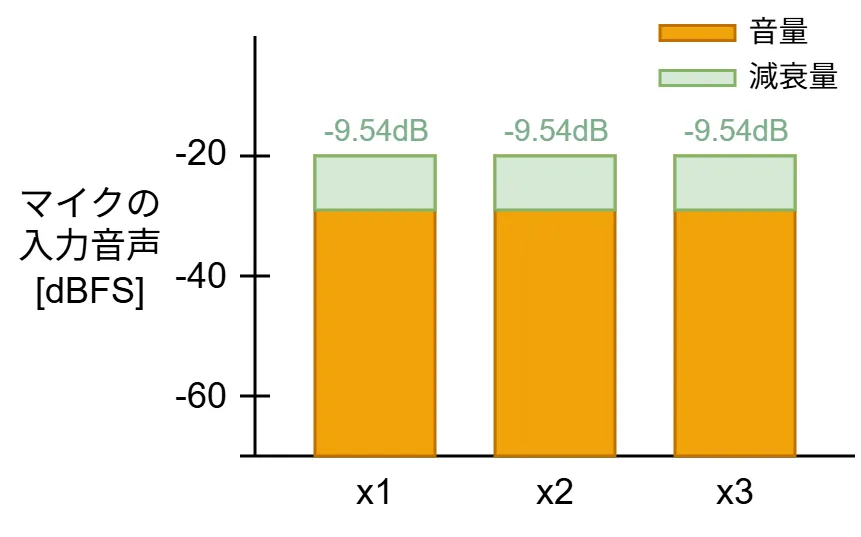
全員が話すときは上図のようにマイクの入力音が均等に減衰されます。
こんな感じで直接音が入らないマイクの入力信号に対しては大きく減衰させるというのが Dugan Automixerの動作となります。
プログラム
Dugan Automixerのソースコード dugan_automixer.pyは以下です。
import numpy as np
import soundfile as sf
import scipy.signal as sg
eps = 1e-10
def dugan_automixer(x, win):
"""
Dugan Automixer
Parameters
----------
x : ndarray (n_mic, n_sample)
Observed signal matrix
n_mic: number of sensors
n_sample: number of samples
win : ndarray (n_win)
Smoothing window function
n_win: The size of the window function
Returns
-------
mix : ndarray (n_sample,)
"""
n_mic = x.shape[0]
n_sample = x.shape[1]
# 減衰量を計算
x_abs = np.abs(x)
x_sum = np.sum(x_abs, axis = 0)
alpha = x_abs / (x_sum + eps)
# ヒルベルト変換で包絡線取得
analytic = sg.hilbert(alpha)
envelope = np.abs(analytic)
# 平滑化(移動平均)
alpha_sm = np.zeros_like(x)
for i in range(4):
smoothed = np.convolve(envelope[i,:], win, mode='full')
smoothed = smoothed[:n_sample]
alpha_sm[i,:] = smoothed
# alpha を乗算
x = x * alpha_sm
# ミキシング
mix = np.sum(x, axis = 0)
return mix
# パラメータ
dir_name = "mic/" # 録音ファイルの場所
n_mic = 4 # 録音ファイルの数
win = np.hanning(128) # 平滑化用の窓関数
# 窓の正規化
win = win/np.sum(win)
# 変数初期化
wav_path = dir_name+"mic0.wav"
data, fs = sf.read(wav_path)
x=np.zeros((n_mic,len(data)))
# WAVファイルを読み込む
for i in range( n_mic ):
wav_path = dir_name+"mic"+str(i)+".wav"
data, fs = sf.read(wav_path)
x[i,:] = data
# 比較用の単純ミキシング
mix = np.sum(x, axis = 0)
# Dugan Automixer で自動ミキシング
y = dugan_automixer(x, win)
# ノーマライズ
norm = np.max(np.abs(mix))
mix = mix / norm
y = y / norm
# WAVファイルを書き込む
sf.write("mix.wav", mix, fs, subtype="PCM_24")
sf.write("dugan_mix.wav", y, fs, subtype="PCM_24")
※減衰量についてはヒルベルト変換で包絡線を抽出したのち、窓関数で平滑化してます。
実験
実際の会議の録音データを使用して、Dugan Automixerの動作を確認してみました。
会議の音声は AMI Meeting Corpus のデータセットを使用しています。会議室の様子は以下です。

各4人がヘッドセットをつけており、シナリオなしで会話をしています。その音声をDugan Automixerでミックスして単純なミックスと比較して動作を確認しました。
ミキシングした結果が以下です。
0:00 / 0:00
0:00 / 0:00
比較すると、明確に違いを感じるのは背景音の大きさですかね。やはり Dugan Automixerのほうが裏の機械音があまりなかったです。
また、同時に複数の話者が話すときの音量が Dugan Automixer のほうが適切に感じました。単純なミックスでは話者が同時に喋るとき、音が急激に大きくなって、かなりびっくりしました。
あとは、気のせいかもしれませんが Dugan Automixer のほうがクリアな音声に聞こえました。かぶりの音声が抑制されるため、Dugan Automixerのほうがクリアなのではと思います(プラシーボ効果かもしれませんが...)。
Dugan Automixerは単純なアルゴリズムですが、それでもかなり効果を実感できるので、現在でも使用されている理由がなんとなくわかります。
おわりに
本記事では Dugan Automixer による自動ミキシングについて紹介しました。
勝手に音量を減衰されたら困るのではないかと思っていましたが、実際に適用してみたら会議の音声が聴きやすくなってましたね。実験で効果を実感できたので、音響機器に Dugan Automixer が入っていたら、今度使ってみようかなと思います。
■参考文献
[1] D. W. Dugan, "Automatic microphone mixer," U.S. Patent 3,992,584, Nov. 16, 1976.
■使用した音声について
この記事で使用した会議音声は AMI Meeting Corpus で提供されているNon Scenario Meetings ISSCO-IDIAP IB4001 のヘッドセット音声を使用させていただきました。
【音声のページ】
・公式サイト: http://groups.inf.ed.ac.uk/ami/corpus/
・引用: Carletta, J., et al. (2005). The AMI Meeting Corpus.