

ビームフォーミングで特定方向の音源を強調してみました。ビームフォーミングとは所定の方向に波(電波、音波など)の指向性を高める技術のことです(Wikipediaより)。
今回は一番基本的なビームフォーマである 遅延和ビームフォーマ(DSBF:Delay and Sum Beam Former)を Python で実装しました。また、室内音響シミュレーションで効果を確かめてみました。
DSビームフォーマ
概要
DSビームフォーマでは複数のマイクを並べて音を録音します。マイクの代表的な並べ方には直線状か円状がありますが、今回は直線状に並べて考えていきます。
1つの平面波だけ存在すると考えると、図のようにマイクで録音される信号(観測信号)に遅延が発生します。
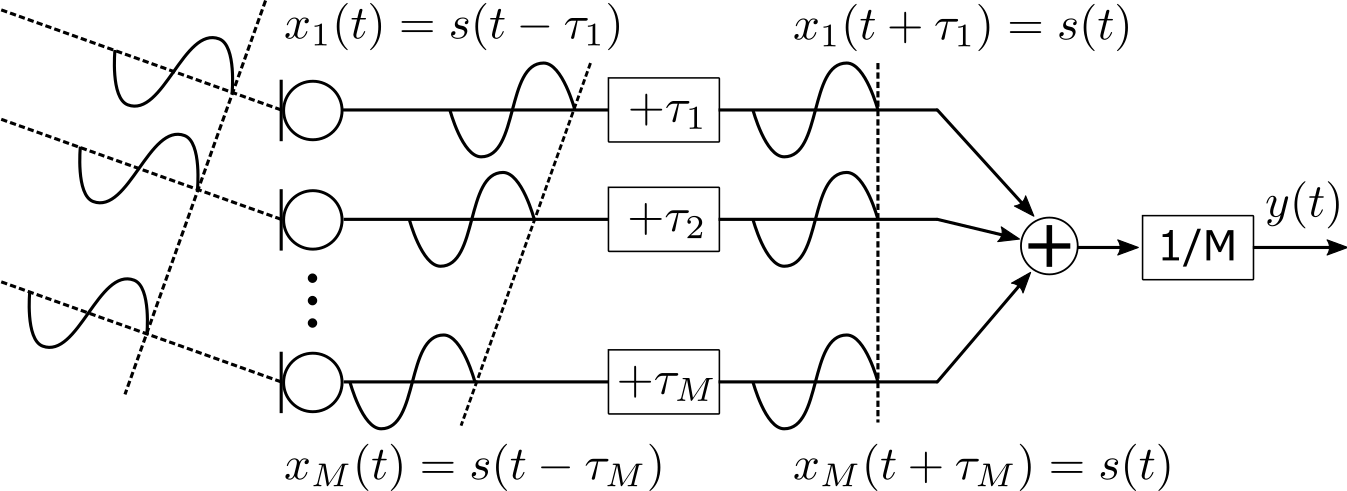
そこで、DSビームフォーマでは\( \tau_m\) だけ時間を進ませて時間遅れをなくします。そうすると、すべてのチャネルで信号の位相がそろいますので、信号を足し合わせることで平面波が到来する方向の音を強調することができます。
一方、他の方向から到来する信号は位相がずれて足し合わされるので、減衰します。
以上がDSビームフォーマの概要となっています。
直線状アレイの遅延
図のように直線状にマイクを配置した場合の中心からの遅延時間について考えていきます。ビームフォーマでは絶対的な遅延時間ではなく、相対的な遅延時間差が重要となりますので、音源ではなく別の場所からの遅延時間を考えても問題ないです。
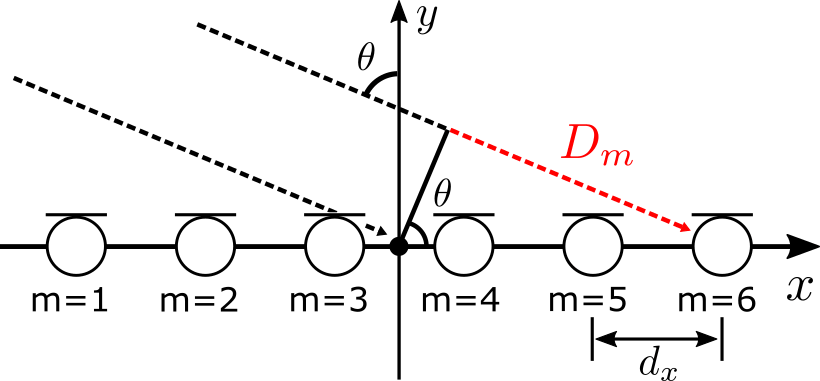
図の\(\ \theta\) 方向から平面波が到来した場合、赤い点線の距離\(\ D_m\) は以下のように表せます。
$$
\begin{equation}
D_m=\left((m-1)-\frac{M-1}{2}\right) d_x \sin{\theta}
\end{equation}
$$
ここで、\( d_x\) はマイクの間隔 [m]、\( M\) はマイクの個数です。
そのため、\( c\) を音速 [m/s] とすると、m番目のマイクにおける遅延時間は次式のように計算されます。
$$
\begin{equation}
\tau_m=\left((m-1)-\frac{M-1}{2}\right) \frac{d_x}{c} \sin{\theta}
\end{equation}
$$
周波数領域
DSビームフォーマを周波数領域かつデジタル信号で考えていきます。時間領域でもDSビームフォーマはできますが、周波数領域ではアナログな遅延時間を扱えるというメリットがあります。
時間領域のデジタル信号で時間進み\(\ \tau_m\) のある信号は左辺、それをSTFTしたものは右辺のように表せます。ここで、fsはサンプリング周波数、i はフレーム番号、k は周波数ビン番号、NはFFT点数です。
$$
\begin{equation}
x_m[n+\tau_{m} f_{s}] \xrightarrow{STFT} \exp{\left(j 2\pi \frac{k}{N}f_{s} \tau_{m}\right)}X_{m}[i, k]
\end{equation}
$$
時間領域の左辺では\( \tau_m f_s\) は整数ではないので、小数点以下を四捨五入などして整数にする必要があり、きちんと他の観測信号と位相を揃えることができません。
一方、短時間フーリエ変換(STFT)した右辺の周波数領域では、\( \tau_m f_s\) が整数でなくても扱えますので、きちんと他の観測信号と位相を揃えることができます。
このようなメリットがあるので、STFTした信号を扱っていきます。
アレイマニフォールドベクトル
音源信号と観測信号の周波数領域における関係を行列で表現します。
周波数領域の音源信号を\(\ S[i,k]\ \)とすると、周波数領域の観測信号\(\ X_m[i,k]\ \)は以下のように表せます。
$$
\begin{align}
x_{m}[n] &= s[n-f_{s}\tau_{m}] \\
& ↓ {\small STFT} \\
X_{m}[i, k] &= \exp{\left(-j 2\pi \frac{k}{N}f_{s} \tau_{m}\right)}S[i, k]
\end{align}
$$
これを行列で表現すると以下のように表せます。
$$
\begin{equation}
\begin{bmatrix}
X_{1}[i,k] \\
\vdots \\
X_{M}[i,k]
\end{bmatrix}=
\begin{bmatrix}
\exp{\left(-j 2\pi \frac{k}{N}f_{s} \tau_{1}\right)} \\
\vdots \\
\exp{\left(-j 2\pi \frac{k}{N}f_{s} \tau_{M}\right)}
\end{bmatrix}
S[i, k]
\end{equation}
$$
ここで、
$$
\begin{equation}
\boldsymbol{a}[k]=
\begin{bmatrix}
\exp{\left(-j 2\pi \frac{k}{N}f_s \tau_1 \right)} \\
\vdots \\
\exp{\left(-j 2\pi \frac{k}{N}f_s \tau_M \right)}
\end{bmatrix}
\end{equation}
$$
はアレイマニフォールドベクトルと呼ばれ、音源定位や音源分離で重要なものとなります。
このアレイマニフォールドを打ち消したいので、次のようなベクトル\(\ \boldsymbol{w}^H\)を考えます。
$$
\begin{equation}
Y[k,i] = \boldsymbol{w}^H[k] X_m[i, k] = S[i, k]
\end{equation}
$$
この\(\ \boldsymbol{w}^H\) は以下のように計算できます。
$$
\begin{equation}
\boldsymbol{w}^H[k] = \frac{\boldsymbol{a}^H[k]}{M}
\end{equation}
$$
\( \boldsymbol{w}^H\) はステアリングベクトルと呼ばれ、ビーム方向(強調する方向)を決定するものとなっています。取り出したい音源方向のステアリングベクトルを計算して、観測信号との行列積を求めれば、その方向の音源だけ強調することができます。
プログラム
作成したDSビームフォーマのプログラム dsbf.py は以下です。
import soundfile as sf
import numpy as np
import scipy.signal as sg
# パラメータ
dir_name = "mic/" # 録音データがあるディレクトリ
n_mic = 64 # マイクの数
theta = 120 # 強調する方向 [度]
d = 0.01 # マイク間の距離 [m]
N = 256 # 窓の大きさ
c = 340 # 音速 [m]
window = "hann" # 窓の種類
# WAVファイル名のリスト作成
wav_list = []
for i in range(n_mic):
wav_list.append("mic"+str(i)+".wav")
# WAVファイルを読み込む
for i, wav_name in enumerate(wav_list):
x, fs = sf.read(dir_name+wav_name)
if i==0:
audio=np.zeros((n_mic,len(x)))
audio[0,:] = x
else:
audio[i,:] = x
# 短時間フーリエ変換(STFT)を行う X.shape=(M, K, I)
f, t, X = sg.stft(audio, fs, window=window, nperseg=N)
# 直線状アレイのアレイ・マニフォールド・ベクトル
n_bin = N//2+1 # ビンの数
a = np.zeros((n_bin, n_mic, 1), dtype=np.complex64)
theta = np.radians(theta) # deg -> rad 変換
for k in range(n_bin):
fk = fs*k/N # 周波数
for m in range(n_mic):
delay = (m-(n_mic-1)/2)*d*np.sin(theta)/c # 遅延時間
a[k,m,0] = np.exp(-1j*2*np.pi*fk*delay)
# ステアリングベクトル
w = np.zeros((n_bin, 1, n_mic), dtype=np.complex64)
for k in range(n_bin):
w[k,:,:] = np.conj(a[k,:,:].T)/n_mic
# ステアリングベクトルをかける
Y = np.einsum("ksm,mki->ski", w, X)
# 逆短時間フーリエ変換(ISTFT)を行う
t, y = sg.istft(Y, fs=fs, window=window, nperseg=N)
# ファイルに書き込む
sf.write("soundout_m8.wav", y[0], fs, subtype="PCM_16")
28~29行目:波形データを短時間フーリエ変換しています。scipy signal の stft で マイクの個数分の波形データを一気にスぺクトログラムに変換しています。フレームシフト点数は指定しない場合、窓関数の大きさの半分となっています。
31~39行目:周波数ビンごとに遅延時間を計算して、直線状アレイのアレイマニフォールドベクトルを作成しています。
41~44行目:アレイマニフォールドベクトルからステアリングベクトルを作成しています。
46~47行目:周波数ビンごとに観測信号をSTFTしたものとステアリングベクトルの行列積を計算しています。計算にはアインシュタインの縮約記法を使えるnumpy einsum を用いています。
シミュレーション実験
室内音響シミュレーションで作成した音にDSビームフォーマを作用させ、特定方向の音だけ強調してみました。
方法
室内音響シミュレーションにはPythonのライブラリであるPyRoomAcousticsを用いました。
シミュレーション上で図のように音源とマイクを配置して、64個のマイクで音楽データを録音しました。
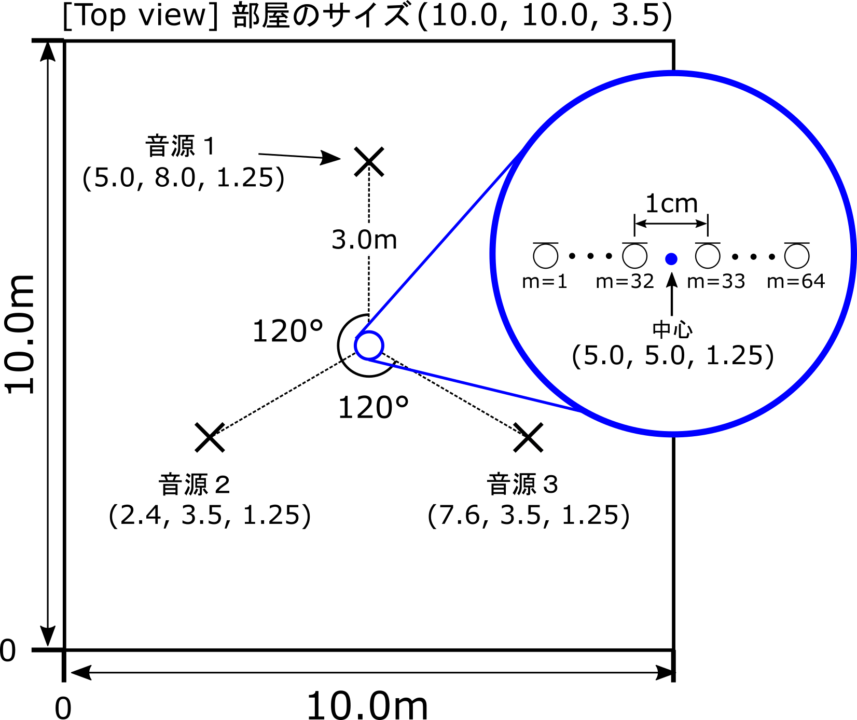
音源1~音源3の音は以下のようになります。
音源1
音源2
音源3
残響時間は0.4秒、収録時のサンプリング周波数は16kHz に設定して、音源2の音だけ強調してみました。
以下をクリックすると、シミュレーションに用いた Python のコード room_sim.py が展開されます。
room_sim.py(クリックで展開)
import numpy as np
import pyroomacoustics as pra
import soundfile as sf
from librosa import resample
fs = 16000 # リサンプリング後の周波数
rt60_tgt = 0.4 # 残響時間
room_size = [10, 10, 3.5] # 部屋の大きさ
SNR = 90 # SN比
dir_src = "src/" # 音源のフォルダ
dir_mic = "mic/" # 録音したデータのフォルダ
src_list = ["sound1.wav", "sound2.wav", "sound3.wav"]
# 音源とマイクの位置を決定
center = [5.0,5.0] # 中心の位置
s_num = 3 # 音源の数
phi0 = 90 # 一個目の音源の方向 [度]
radius = 3 # 音源の中心から距離 [m]
m_num = 64 # マイクの数
d = 0.01 # マイクの間隔 [m]
# 音源を円状アレイで配置
phi0 = np.radians(phi0) # deg -> rad 変換
s_locs = pra.circular_2D_array(center, s_num, phi0, radius)
s_locs = np.insert(s_locs, 2, 1.25, axis=0)
# マイクを線状アレイで配置
m_locs = pra.linear_2D_array(center, m_num, 0, d)
m_locs = np.insert(m_locs, 2, 1.25, axis=0)
# WAVファイルを読み込む
audio = []
for i, src_name in enumerate(src_list):
x, fs_tmp = sf.read(dir_src+src_name)
x = resample(x, fs_tmp, fs)
audio.append(x)
audio = np.array(audio)
# 残響時間と部屋の大きさから吸音率と反射回数を決定
e_absorption, max_order = pra.inverse_sabine(rt60_tgt, room_size)
# 部屋の作成
room = pra.ShoeBox(
room_size, fs=fs, materials=pra.Material(e_absorption), max_order=max_order
)
# 部屋に音源を配置
for i in range(s_num):
room.add_source(s_locs[:,i], signal=audio[i,:], delay=0)
# 部屋にマイクを配置
room.add_microphone_array(
pra.MicrophoneArray(m_locs, fs=fs)
)
# シミュレーションする
room.simulate(snr=SNR)
# マイクで録音した音を書き出す
mic_data = room.mic_array.signals
mic_data = mic_data/np.max(np.abs(mic_data)) # ノーマライズ
for i in range(m_num):
name = dir_mic+"mic"+str(i)+".wav"
sf.write(name, mic_data[i,:], fs, subtype='PCM_16')
結果
DSビームフォーマを用いて音源2を強調した結果は以下のようになりました。参考としてマイク(m=32)で録音したデータも載せておきます。
マイクの録音データ (m=32)
処理結果
音源2の音だけ取り出されて、他の音は減衰しているのがわかると思います。
補足:はじめ、マイクの個数 M=8 で実験を行ったのですが、効果は以下のようになんとなくわかる程度でした。
マイクの個数 M=8 の処理結果
人間の感覚の大きさは受ける刺激の強さの対数に比例するというウェーバー・フェヒナーの法則があるので、音源を8倍大きくしても感じる音の大きさは8倍にはならないということかなと思います。
おわりに
DSビームフォーマを用いて特定方向の音源を強調してみました。DSビームフォーマの有効性を実感するのに64個のマイクを使う必要があるのは驚いています。DSビームフォーマは64個のマイクを1㎝間隔で配置する必要があるので、実際の環境で用いるのはかなり難しそうですね。
■参考文献
[1] 浅野太、”音のアレイ信号処理 音源の定位・追跡と分離”、コロナ社、2011.
[2] 戸上真人、”機械学習実践シリーズ Pythonで学ぶ音源分離”、インプレス、2020.
■使用した楽曲について
この記事で信号処理した楽曲は Pixabay で提供されているものを使用させていただきました。
【音源1】
"I'M JEALOUS" 2024 KELLEPICS (Public Domain)
【音源2】
"Neon Skies" 2024 TheDigitalArtist (Public Domain)
【音源3】
"Stomping (Drums rhythm and Percussion)" 2023 Alex_Kizenkov (Public Domain)
■変更履歴
・2024/12/23:文章の整理