

どうぶつの森の住民の声がどのように作られているか興味があったので、どうぶつ語への音声変換を少し試してみました。
ちなみに筆者は「どうぶつの森64」しかプレイ経験がないです。
どうぶつ語の解析
まず、どうぶつ語を音声解析しました。Youtube の実況なしプレイ動画から音を抽出して、まめきちの声をスペクトログラム解析してます。セリフは以下です。
移住された みなさんのために、ちょっとした日用品などを販売させて いただいています!
スペクトログラムの解析結果は以下です(BGMも少し混ざっています)。
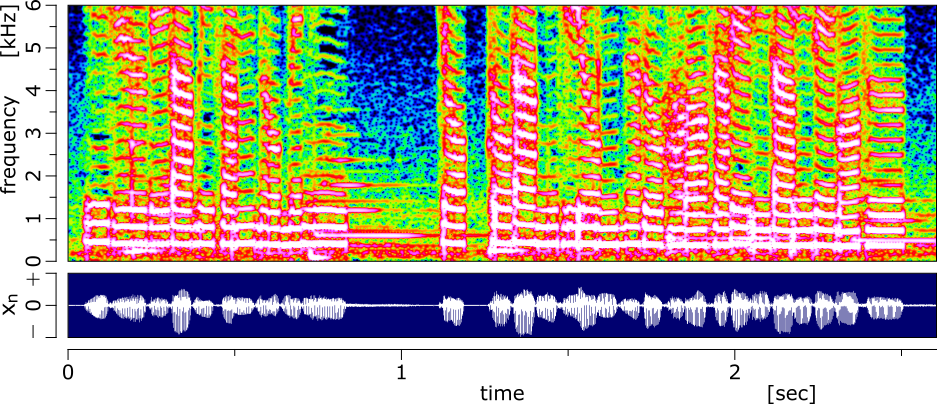
解析結果をみると、普通の音声のスペクトログラムに近く、人工的な感じはあまりないです。違いがあるとすると、基本周波数が400Hzくらい?で基本周波数の変化が少ないところです。
おそらく、他の人が解説しているように一文字ずつ録音して、波形接続を行い、早送り再生させているのでは?と思います。
どうぶつ語の音声変換
早送り再生
とりあえず、早送り再生させてみて、どうぶつ語に近づくか確認してみます。
作成した早送り再生のソースコードは以下です。リサンプリングを使用して、早送り再生をしています。
import soundfile as sf
import resampy
# パラメータ
speed = 2.2 # 話速[倍]
# WAVファイルを読み込む
x, fs = sf.read("input.wav")
# 早送り再生(リサンプリング)
fs_new = int(fs/speed)
y = resampy.resample(x, sr_orig=fs, sr_new=fs_new)
# WAVファイルを書き込む
sf.write("output1.wav", y, fs)
2.2倍に早送り再生した結果が以下になります。
入力音声
早送り再生の音声(話速:2.2倍)
どうぶつ語に少し近づいた気がします。
スペクトログラムは以下です。
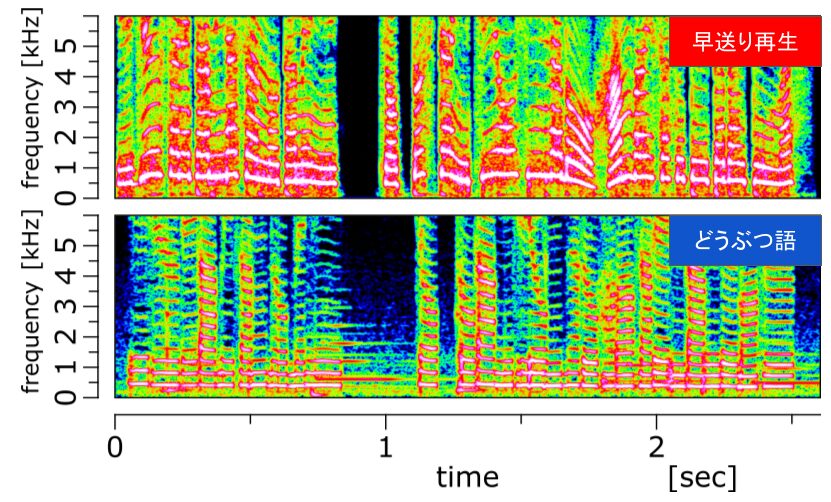
音の高さも話速も近づいていますが、早送り音声のほうが基本周波数の変化が激しいという感じです。
抑揚をなくす
つぎは基本周波数の変化を抑制して、声の抑揚をなくしてみます。
作成したソースコードは以下です。音声分析合成システム WORLD のPythonラッパーである PyWorld を使用しています。
import soundfile as sf
import resampy
import pyworld as pw
# パラメータ
speed = 2.2 # 話速 [倍]
f0_base = 200 # 基本周波数
# WAVファイルを読み込む
x, fs = sf.read("ijusareta.wav")
# 基本周波数、スペクトル包絡、非周期指標の抽出
_f0, t = pw.dio(x, fs) # 基本周波数の抽出
f0 = pw.stonemask(x, _f0, t, fs) # 基本周波数の修正
sp = pw.cheaptrick(x, f0, t, fs) # スペクトル包絡の抽出
ap = pw.d4c(x, f0, t, fs) # 非周期性指標の抽出
# 基本周波数の変化の抑制
f0[f0>0] = (f0[f0>0] - f0_base) * 0.1 + f0_base
synthesized = pw.synthesize(f0, sp, ap, fs)
# 早送り再生(リサンプリング)
fs_new = int(fs/speed)
y = resampy.resample(synthesized, sr_orig=fs, sr_new=fs_new)
# WAVファイルを書き込む
sf.write("output2.wav", y, fs)
19行目で下図のように基本周波数 F0 と f0_base の距離が0.1倍になるようにしています。
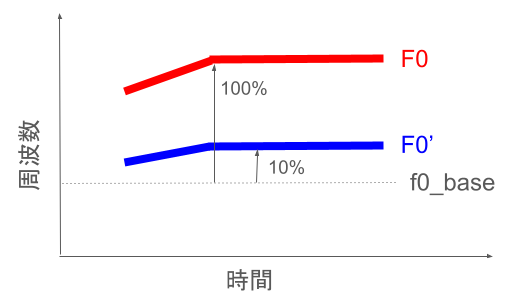
また、PyWorld では基本周波数を推定できていない箇所は 0 が格納されているので、0 の箇所は計算を除外しています。
音声変換した結果は以下になります。
入力音声
抑揚をなくした音声(f0_base=200Hz)
かなりどうぶつ語に近づいたのでは?
スペクトログラムを比較した結果は以下です。
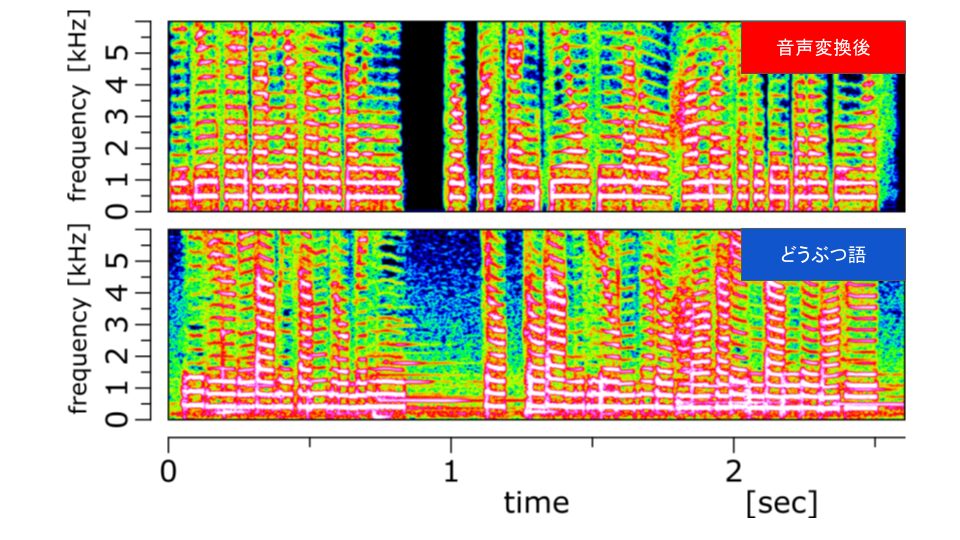
スペクトログラムもどうぶつ語にだいぶ近づいた気がします。
ちなみに、f0_base=100Hzとすると、別のどう森の住民の声に聞こえます。
抑揚をなくした音声(f0_base=100Hz)
おわりに
本記事ではどう森の住民の声に音声変換してみました。結構似ているように音声変換できたのでは?と思います。
さらなる改善案としては、どうぶつ語は2文字間隔で発音されているらしいので、音素の区間を判別して、2文字間隔で発音するようにすればよいかと思います。ただ、かなり手間がかかりそうなので、ここでは辞めておきます。
■使用した読み上げ音声について
この記事では SPEECHGEN.IO の読み上げ音声を使用させていただきました。