
タイムストレッチで早送り再生してみました。タイムストレッチとは音の高さ(ピッチ)を変化させずにテンポを変更する処理のことです。
今回は再生速度2.0倍まで可能なタイムストレッチのアルゴリズムを実装しました。
タイムストレッチ実現の概要
音声「あ」の波形を以下に示します。
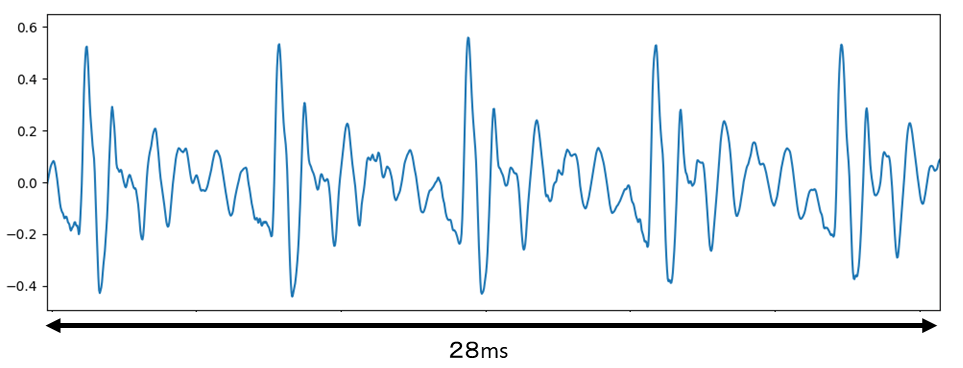
音声は図のように部分的には周期性をもち、30msくらいであればその性質は変わりません。
このことを利用して、タイムストレッチを実装します。
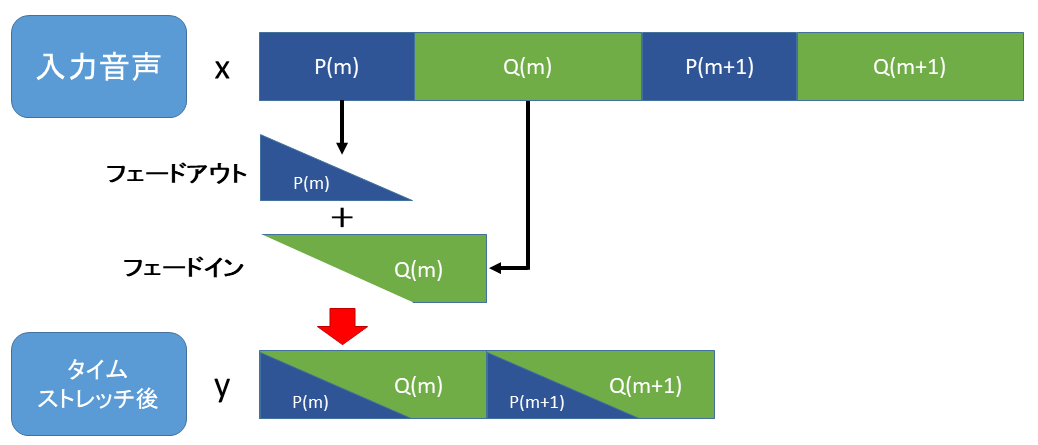
ざっくり説明すると下図のように周期の一部の波形を切り取ることで話速を速めます。
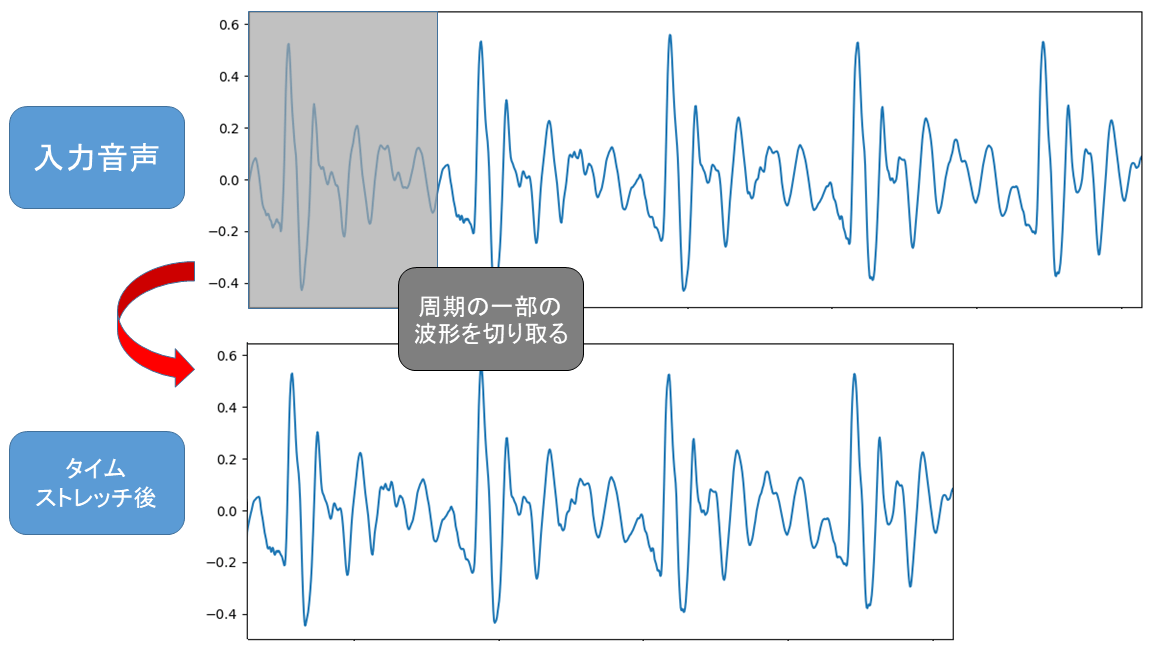
実際は波形の一部を切り取るとノイズが発生するため、クロスフェードによってノイズを抑えます。クロスフェードについては後述します。
タイムストレッチの方法
タイムストレッチは約20msおきに以下の処理を繰り返すことで実現します。
- 音声の周期Pを求める
- 切り詰める波形の長さQを決定
- クロスフェードで接続
音声の周期Pを求める
音声の周期を求める方法はいくつかありますが、今回は自己相関関数を使っていきます。
以下の自己相関関数\(R_{xx}\)のピークを調べることで周期Pが求められます。
$$
R_{xx}[\tau] = \sum_{n}^{N-1} x[n]x[n+\tau]
$$
自己相関関数のピークで周期が求まる理由は以下のように\(\ \tau \ \) が周期であれば、波形の正負が揃い、掛け算の総和が大きくなるからです。
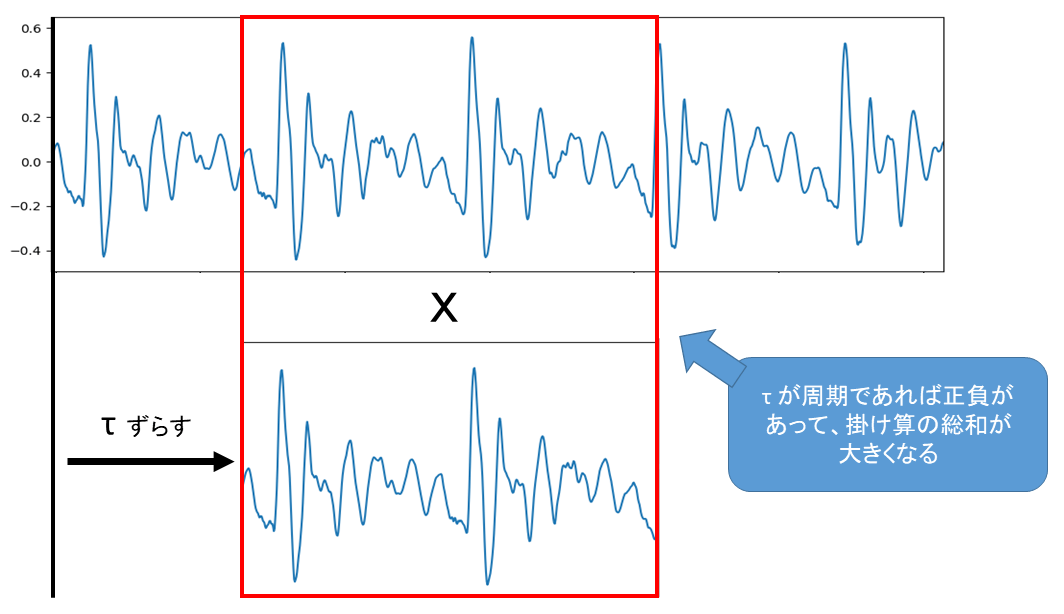
もちろん、\(\tau=0\ \)のときが最大値となってしまうので、\(\tau=0\) は除きます。
切り詰める波形の長さQを決定
今回、タイムストレッチの波形の切り詰め方は以下の図のようにします。
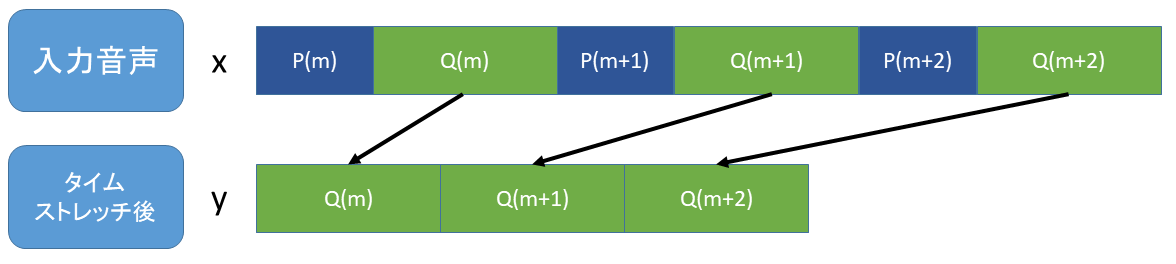
上記のQは再生速度 r [倍] と周期Pから求めます。
再生速度が r のとき、信号長は 1/r となります。このことから以下の式が成り立つようにQを決定します。
$$
\frac{1}{r} = \frac{Q}{P+Q}
$$
式変形すると以下です。
$$
Q = {\rm round}\left(\frac{P}{r-1}\right)
$$
クロスフェードで接続
単純に1周期分の波形を切り取るとノイズが発生してしまいますので、クロスフェードを導入します。
クロスフェードとは前の音を徐々に小さく(フェードアウト)しながら次の音を徐々に大きく(フェードイン)することで波形を接続する方法です。
今回は下図のようにPをフェードアウト、Qをフェードインして波形を接続します。
プログラム
タイムストレッチで早送りするプログラムをPythonで実装しました。ソースコードと実行方法について説明します。
ソースコード
入力データを早送り再生するソースコード speedup.py は以下です。
import soundfile as sf
import numpy as np
import scipy.signal as sg
# パラメータ
r = 1.2 # 再生速度 [倍]
P_upper = 20 # 周期Pの上限 [ms]
P_lower = 5 # 周期Pの下限 [ms]
wav_in_name = "input.wav" # 入力音データ名
wav_out_name = "output.wav" # 出力音データ名
# WAVファイルを読み込む
x, fs = sf.read(wav_in_name)
# 必要な値を設定
length_x = x.shape[0] # 入力信号の長さ
y = np.zeros(int(length_x/r)) # 出力信号
P_upper_n = P_upper * fs // 1000 # [ms]->[sample]
P_lower_n = P_lower * fs // 1000 # [ms]->[sample]
# 繰り返し処理
pos_x = 0
pos_y = 0
while pos_x + P_upper_n*2 < length_x:
# 自己相関関数を求める
x1 = x[pos_x:pos_x+P_upper_n*2]
x2 = x[pos_x:pos_x+P_upper_n]
Rxx = sg.correlate(x1, x2, mode="valid")
# P と Q を求める
P = np.argmax(Rxx[P_lower_n:]) + P_lower_n
Q = round(P/(r-1))
# フェードアウトとフェードイン
fadeout = np.linspace(1.0, 0.0, P) * x[pos_x:pos_x+P]
fadein = np.linspace(0.0, 1.0, P) * x[pos_x+P:pos_x+P*2]
# 出力信号を作成
y[pos_y:pos_y+P] = fadeout + fadein # クロスフェード
y[pos_y+P:pos_y+Q] = x[pos_x+2*P:pos_x+P+Q]
# 繰り返し処理の次の位置に更新
pos_x += P + Q
pos_y += Q
if np.max(np.abs(y)) > 1.0:
y = y/np.max(np.abs(y)) # ノーマライズ
sf.write(wav_out_name, y, fs, subtype='PCM_16')24行目:自己相関を求める時間区間(P_upper * 2)がなければ繰り返し処理を終了する。そのため、WAVデータの終端付近は出力信号がないです。
26~29行目:0~P_upper [ms] で自己相関を求める。
32行目:P については P_lower~P_upper [ms] における最大値を求める。
47~48行目:オーバーフローしたときにノーマライズする。
実行方法
(1) プログラムを実行するディレクトリにソースコード(speedup.py)と入力 WAV データを格納する。
(2) ソースコード5~10行目のパラメータと入出力データ名を修正する。
# パラメータ
r = 1.2 # 再生速度 [倍]
P_upper = 20 # 周期Pの上限 [ms]
P_lower = 5 # 周期Pの下限 [ms]
wav_in_name = "input.wav" # 入力音データ名
wav_out_name = "output.wav" # 出力音データ名
(3) 以下のコマンドで python を実行することで、早送り再生されたWAVデータが出力される。
$ python speedup.py処理結果
以下のようにパラメータを設定して、音声を早送り再生しました。
| パラメータ名 | 変数名 | 設定値 |
|---|---|---|
| 再生速度 | r | 1.2, 1.5, 2.0 [倍] |
| 周期Pの上限 | P_upper | 20 [ms] |
| 周期Pの下限 | P_lower | 5 [ms] |
タイムストレッチで早送り再生した音声は以下のようになります。
入力音声
早送り音声(再生速度:1.5倍)
早送り音声(再生速度:2.0倍)
ノイズもあまりなく上手くタイムストレッチができているかなと思います。
おわりに
本記事では、タイムストレッチで早送り再生してみました。案外上手くタイムストレッチできたかなと思います。
追記(2024/12/11):間違って自己相関関数ではなく、畳み込みの計算をしていましたので修正いたしました。
■参考文献
[1] 川村新、”音声音響信号処理の基礎と実践”、コロナ社、2021.
■使用した音声について
この記事で使用した音声は Mozilla Foundation で提供されている音声を使用させていただきました。
【音声のページ】
・ "Common Voice: A Massively-Multilingual Speech Corpus" 2020 Mozilla Foundation (Licensed under CC-0) https://huggingface.co/datasets/mozilla-foundation/common_voice_14_0
■変更履歴
・2024/12/11:処理する音声の変更、プログラムの修正。
・2026/03/30:shellスクリプトのコード表示の不具合を修正