
線形予測分析を用いてスペクトル包絡推定を行いました。
線形予測符号(LPC: linear predictive coding)とも呼ばれていますが、筆者の聞きなじみのある線形予測分析と呼んでいきます。
スペクトル包絡とは
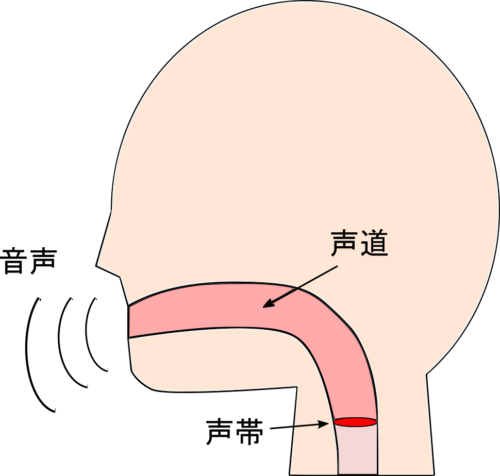
ケプストラム分析によるスペクトル包絡推定 と同じ説明となりますが、ソースフィルタモデルでは声帯の振動を音源、声道による影響をフィルタ(声道フィルタ)として考えます。
数式で説明すると、音声\(\ S\ \)は以下のように表せるということです。
$$
S(\omega) = H(\omega) U(\omega) \tag{1}
$$
ここで、\(U\ \)は声帯振動の周波数特性、\(H\ \)は声道フィルタの周波数特性です。
声道フィルタの振幅特性 \(|H(\omega)|\) についてはスペクトル包絡と呼ばれており、音色や音声の母音 /ieaou/ などを決めるものとなります。
(1)式をz変換した場合は以下の式となります。
$$
S(z) = H(z) U(z) \tag{2}
$$
線形予測分析
声道のモデル化
線形予測分析では声道フィルタを以下の全極型フィルタでモデル化して考えます。
$$
H(z) = \frac{1}{1-\sum_{k=1}^{p}a_{k}z^{-k}} \tag{3}
$$
ここで、\(p\ \)は極の数です。
極の数についてはいろいろと議論されていますが、文献[1]ではサンプリングレート10kHz の音声に対して\(\ p=12\ \)でした。
声道フィルタを全極型フィルタでモデル化するとき、音声信号 \(s[n]\) は以下のように表せます。
$$
s[n] = \sum_{j=1}^{p} a_{k} s[n-j] + u[n] \tag{4}
$$
ここで、\(u[n]\ \)は声帯振動の信号となります。
補足:声道フィルタを(3)式のように全極型フィルタでモデル化する理由としては以下があります[1,2]。
- 鼻音以外の有声音の場合、極だけの伝達関数で表現できるため
- 鼻音や無声音の場合、零点が単位円の中にあり、複数の極で近似できるため
- そもそも、知覚的には零点の影響は極の影響よりも小さいため
- 音響学的には声道を音響管モデルで近似することを意味するため
最後の理由にある音響管モデルの意味は以下です。
音響管モデル
音響管モデルは,声帯から口唇までを断面積の異なる円筒の縦続接続として近似したモデルであり,口の形状が音色に与える影響を観察するための教材として利用される。
引用元:森勢将雅, ”音声分析合成,” コロナ社, 2018, p.55.
音響管モデルの伝達関数も全極型であり、声道フィルタを全極型フィルタで表すのは適しているといえます。
あとは実装面ではレヴィンソン・ダービンアルゴリズムなどを使用して計算を効率化できるという利点もあります。
線形予測係数の推定
(4)式の線形予測係数 \(\ a_{k}\ (1\leq j \leq p) \ \)を推定していきます。
有声音のとき声帯振動については以下のパルス列になると仮定します。
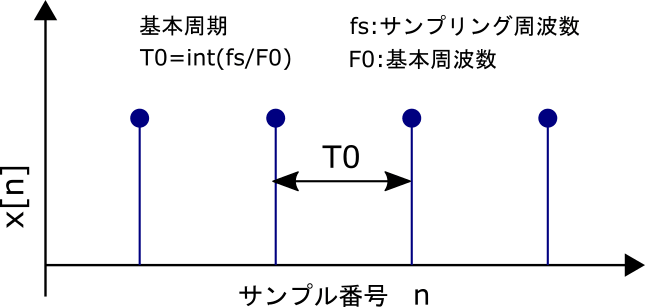
このとき、パルスがない箇所では過去の音声信号から現在の音声信号を以下のように推定できます。
$$
\hat{s}[n] = \sum_{j=1}^{p} a_{j}s[n-j] \tag{5}
$$
推定信号と実際の信号との予測誤差\(\ \epsilon[n]\ \)を計算すると以下です。
$$
\begin{align}
\epsilon[n] &= s[n]-\hat{s}[n] \\
&= s[n]-\sum_{j=1}^{p} a_{j}s[n-j] \tag{6}
\end{align}
$$
補足:声帯振動のパルスがある箇所では予測誤差に声帯振動の信号も含まれていますので、声帯振動の推定信号\(\ \hat{u}[n]\fallingdotseq \epsilon[n]\ \)でもあります。
予測誤差の2乗平均\(\ E\ \) は以下となります。
$$
\begin{align}
E &= \frac{1}{N}\sum_{n=0}^{N-1} \epsilon^{2}[n] \\
&= \frac{1}{N}\sum_{n=0}^{N-1} \left(s[n]-\sum_{j=1}^{p} a_{j}s[n-j]\right)^2 \tag{7}
\end{align}
$$
ここで、\(N\ \)はサンプル数です。
\(E\ \)が最小となる線形予測係数を得るため、\(E\ \)の\(\ a_{i}\ (1\leq i\leq p)\ \)の偏微分を求めて
\begin{align}
\frac{\partial E}{\partial a_{i}} &= \frac{2}{N}\sum_{n=0}^{N-1} \left((-s[n-i])\left(s[n]-\sum_{j=1}^{p} a_{j}s[n-j]\right)\right) \\[5pt] &= \frac{2}{N}\sum_{j=1}^{p} a_{j} \sum_{n=0}^{N-1} s[n-i]s[n-j]-\frac{2}{N}\sum_{n=0}^{N-1} s[n-i]s[n] \tag{8}\\[5pt] \end{align}
$$
\(\partial E / \partial a_{i}=0\ \) と置くと、
\sum_{j=1}^{p} a_{j} \sum_{n=0}^{N-1} s[n-i]s[n-j] = \sum_{n=0}^{N-1} s[n-i]s[n] \tag{9}
$$
それから、\(s[n]\) の自己相関関数を
$$
\phi[i]=\sum_{n=0}^{N-1} s[n-i]s[n] \tag{10}
$$
とおけば、(9)式を以下のように表せます。
$$
\sum_{j=1}^{p} a_{j} \phi[i-j] = \phi[i] \hspace{1em} (1\leq i \leq p) \tag{11}
$$
さらに、これを行列で表現すると以下のように書けます。
$$
{\boldsymbol \Phi}{\boldsymbol a}={\boldsymbol \Psi} \tag{12}
$$
\begin{align}
{\boldsymbol \Phi} &=
\begin{bmatrix}
\phi[0] & \phi[1] & \phi[2] & \cdots & \phi[p-1] \\
\phi[1] & \phi[0] & \phi[1] & \cdots & \phi[p-2] \\
\phi[2] & \phi[1] & \phi[0] & \cdots & \phi[p-3] \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
\phi[p-1] & \phi[p-2] & \phi[p-3] & \cdots & \phi[0] \\
\end{bmatrix} \\[5pt] {\boldsymbol a} &=
\begin{bmatrix}
a_{1} & a_{2} & \cdots & a_{p-1} & a_{p}
\end{bmatrix}^T \\[5pt] {\boldsymbol \Psi} &=
\begin{bmatrix}
\phi[1] & \phi[2] & \cdots & \phi[p-1] & \phi[p] \end{bmatrix}^T
\end{align}
$$
最終的に、逆行列\(\ \boldsymbol \Phi^{-1}\ \)を左から掛けることで線形予測係数を推定することができます。
$$
{\boldsymbol a}={\boldsymbol \Phi}^{-1}{\boldsymbol \Psi} \tag{13}
$$
上記では有声音を仮定しましたが、文献[1]によれば、無声音についても同様に推定できるとのことです。
プログラム
ソースコード
線形予測分析で推定したスペクトル包絡を出力するソースコードは以下です。
import soundfile as sf
import numpy as np
import librosa
from scipy.fft import rfft, irfft
import scipy.signal as sg
import matplotlib.pyplot as plt
# パラメータ
wav_name = "aiueo.wav" # 読み込むWAVデータの名前
graph_name = "graph.png" # 出力するPNGデータの名前
start_ms = 330 # 分析開始点 [ms]
target_fs = 10000 # サンプリング周波数 [Hz]
N_ms = 25 # 切り出す時間 [ms]
p = 12 # 極の数
# WAVファイルを読み込む
s, fs = sf.read(wav_name)
# リサンプリング
s = librosa.resample(s, orig_sr=fs, target_sr=target_fs)
# 高域強調(プリエンファシス)
s = sg.lfilter(b=[1.0,-0.97],a=1,x=s)
# ms -> sample 変換
start = int(target_fs * start_ms / 1000)
N = int(target_fs * N_ms / 1000)
# 窓関数の作成
w = sg.get_window("hann", N) # 窓関数の作成
# 窓関数を掛ける
s1 = s[start:start+N] * w
s2 = s1[:N-p]
# 行列 Φ、Ψ を計算
phi = sg.correlate(s1, s2, mode="valid") # 自己相関関数を求める
Phi_arr = np.zeros((p,p))
Psi_arr = np.zeros((p,1))
lcp_coef = np.zeros((p,1))
## Φ 計算
for i in range(p):
for j in range(p):
Phi_arr[i,j] = phi[abs(i-j)]
## Ψ 計算
for i in range(p):
Psi_arr[i,0] = phi[i+1]
# 線形予測係数を求める
Phi_inv_arr = np.linalg.pinv(Phi_arr)
lcp_coef = np.matmul(Phi_inv_arr, Psi_arr)
# 線形予測係数 a を成形
a_arr = np.zeros(p+1)
a_arr[0] = 1.0
for i in range(1,p+1):
a_arr[i] = -lcp_coef[i-1,0]
# パワースペクトルを求める
eps = np.finfo(np.float64).eps # マシンイプシロン
S_fft = rfft(s1) # FFT
S_log = 20 * np.log10(np.abs(S_fft)+eps) # 対数変換
S_log = S_log - np.mean(S_log) # 平均を引く
f1 = np.arange(N//2+1)*(target_fs/N) # 周波数軸
# スペクトル包絡を求める
f2, H = sg.freqz(b=1, a=a_arr, fs=target_fs)
H_log = 20 * np.log10(np.abs(H)+eps)
H_log = H_log - np.mean(H_log) # 平均を引く
# スペクトル包絡のグラフ出力
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(f1, S_log, c="tab:purple")
ax.plot(f2, H_log, c="tab:red")
ax.set_xlim([0,4000]) # 4kHzまで表示
ax.set_ylim([-25,35])
ax.set_xlabel("Frequency [Hz]")
ax.set_ylabel("Relative Level [dB]")
fig.savefig(graph_name) # スペクトル包絡を出力
22~23行目:声帯振動のスペクトルと口からマイクに放射されるまでの特性(放射特性)を取り除くために高域強調(プリエンファシス)を行います。
63行目と69行目:パワースペクトルとスペクトル包絡を比較しやすいように平均を引きます。
実行方法
(1) プログラムを実行するディレクトリにソースコード(lcp.py)とWAVファイルを格納する。
(2) ソースコード8~14行目のパラメータを修正する。
# パラメータ
wav_name = "aiueo.wav" # 読み込むWAVデータの名前
graph_name = "graph.png" # 出力するPNGデータの名前
start_ms = 330 # 分析開始点 [ms]
target_fs = 10000 # サンプリング周波数 [Hz]
N_ms = 25 # 切り出す時間 [ms]
p = 12 # 極の数
(3) 以下のコマンドで python を実行する。
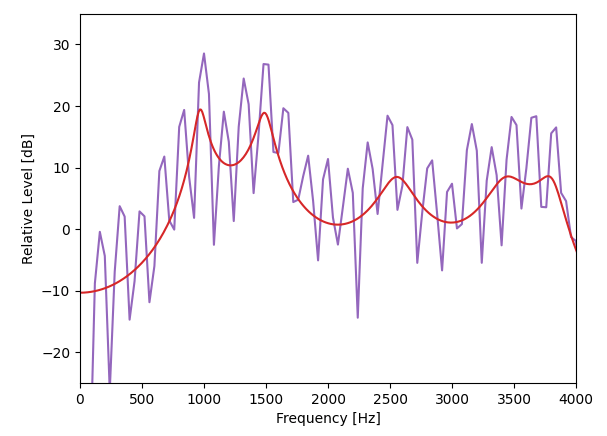
$ python lcp.py以下のように線形予測分析によるスペクトル包絡が出力されます。
線形予測分析の結果
「あいうえお」を以下のようにパラメータを設定して線形予測分析をしました。
| パラメータ名 | 変数名 | 設定値 |
|---|---|---|
| リサンプリング後のFs | target_fs | 10000 Hz |
| 切り出す時間 | N_ms | 25 ms |
| 声道フィルタの極の数 | p | 12 |
スペクトル包絡推定した結果を以下の図に示します。
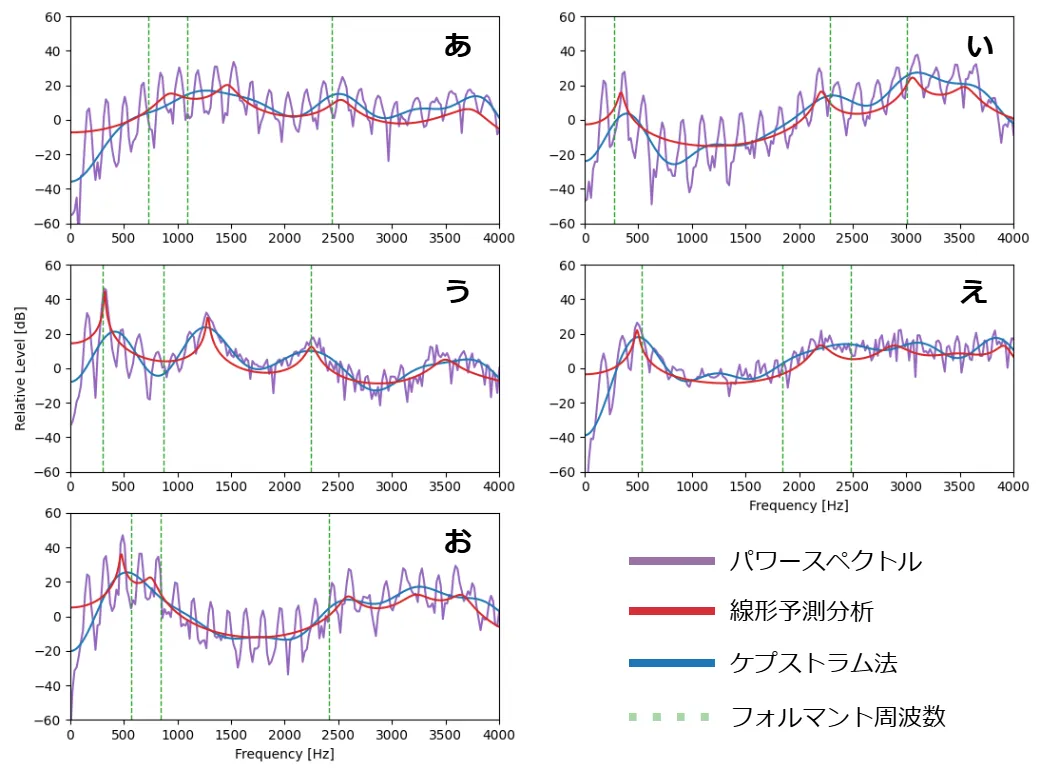
緑の点線は、参考文献 [3] に記載されていた男性33人のフォルマント周波数 F1~F3 の平均です。
ケプストラム法と比べて、線形予測分析のスペクトル包絡のほうが見た目的に精度がよい気がします。
また、ケプストラム法では包絡戦の頂点がはっきりしていないため、フォルマント周波数を決定しにくいですが、線形予測分析は声道フィルタの極の偏角からフォルマント周波数を決定できるので、使いやすい気がします。
補足:記事書いている最中に気づきましたが、文献[1]には声帯振動の特性と放射特性を含む場合は、極の数は2つ増えて12と書いてあったので、高域強調している場合は極の数は10(Fs=10kHz)のほうが良かったかもしれません。ただ、p=10でもF1~F3付近のスペクトル包絡はそこまで変わらなかったので、そのままにしています。
おわりに
線形予測分析を用いてスペクトル包絡の推定を行いました。
ケプストラム法と比較して、フォルマント周波数の推定精度は高そうに感じます。また、個人的にはスペクトル包絡の山が線形予測分析のほうがはっきりしているのが良いかなと思います。
■参考文献
[1] Atal BS, Hanauer SL. "Speech analysis and synthesis by linear prediction of speech wave," J Acoust Soc Am., 50(2), 1971, pp.637–655.
[2] 森勢将雅, ”音声分析合成,” コロナ社, 2018.
[3] 電子情報通信学会、”聴覚と音声”、コロナ社、1973.
■変更履歴
・2025/09/06:文章を少し整理